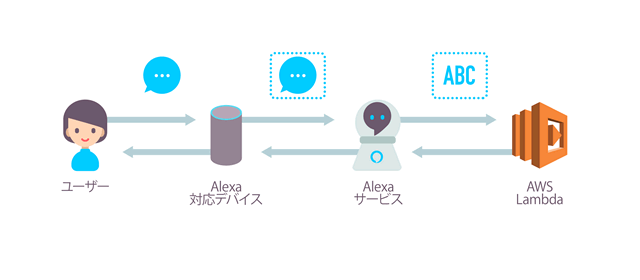
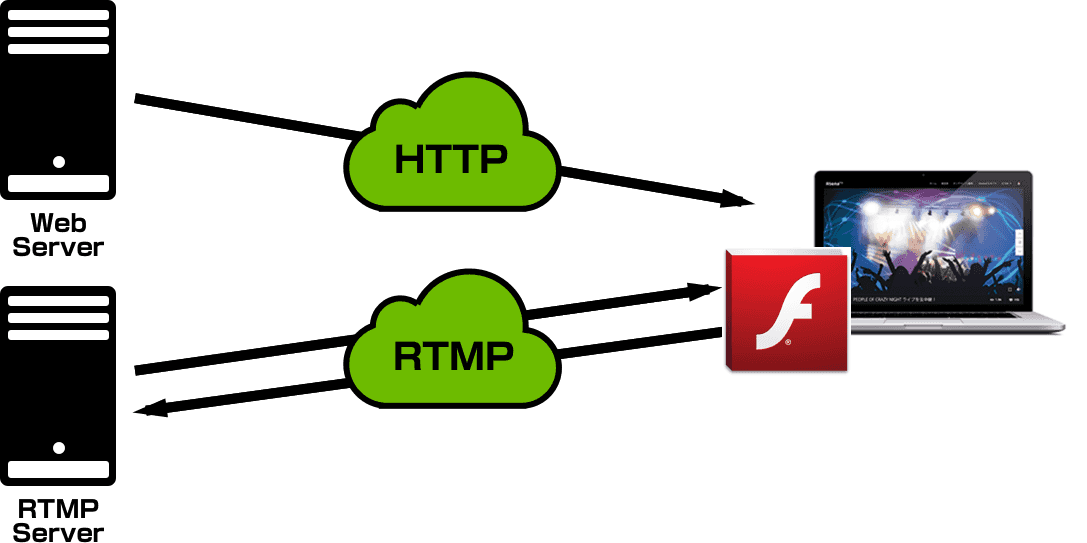
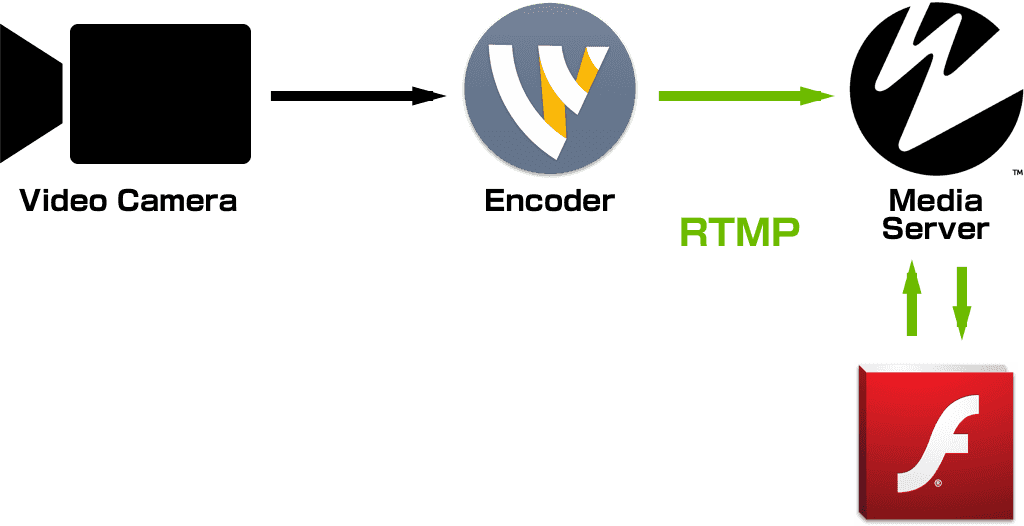
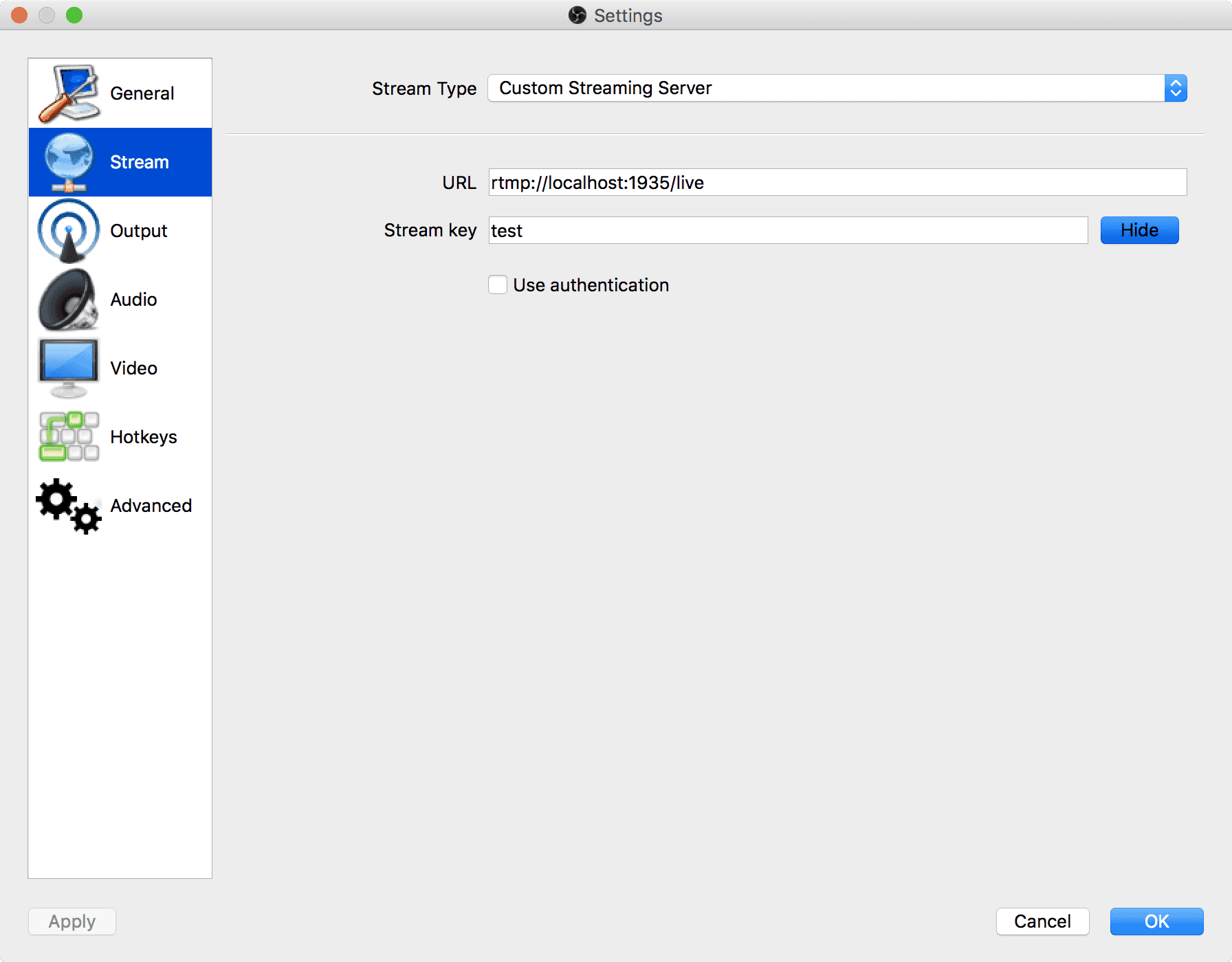
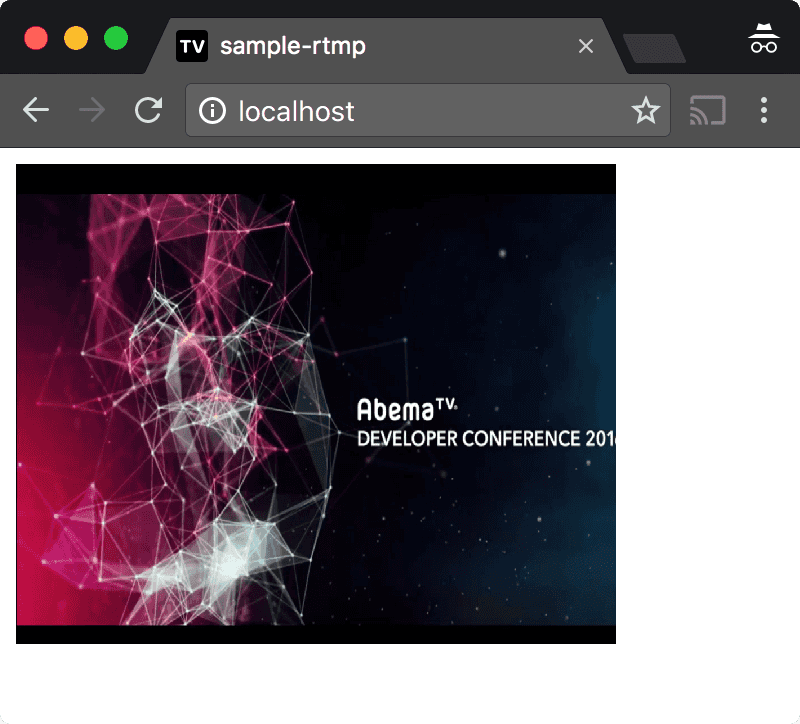
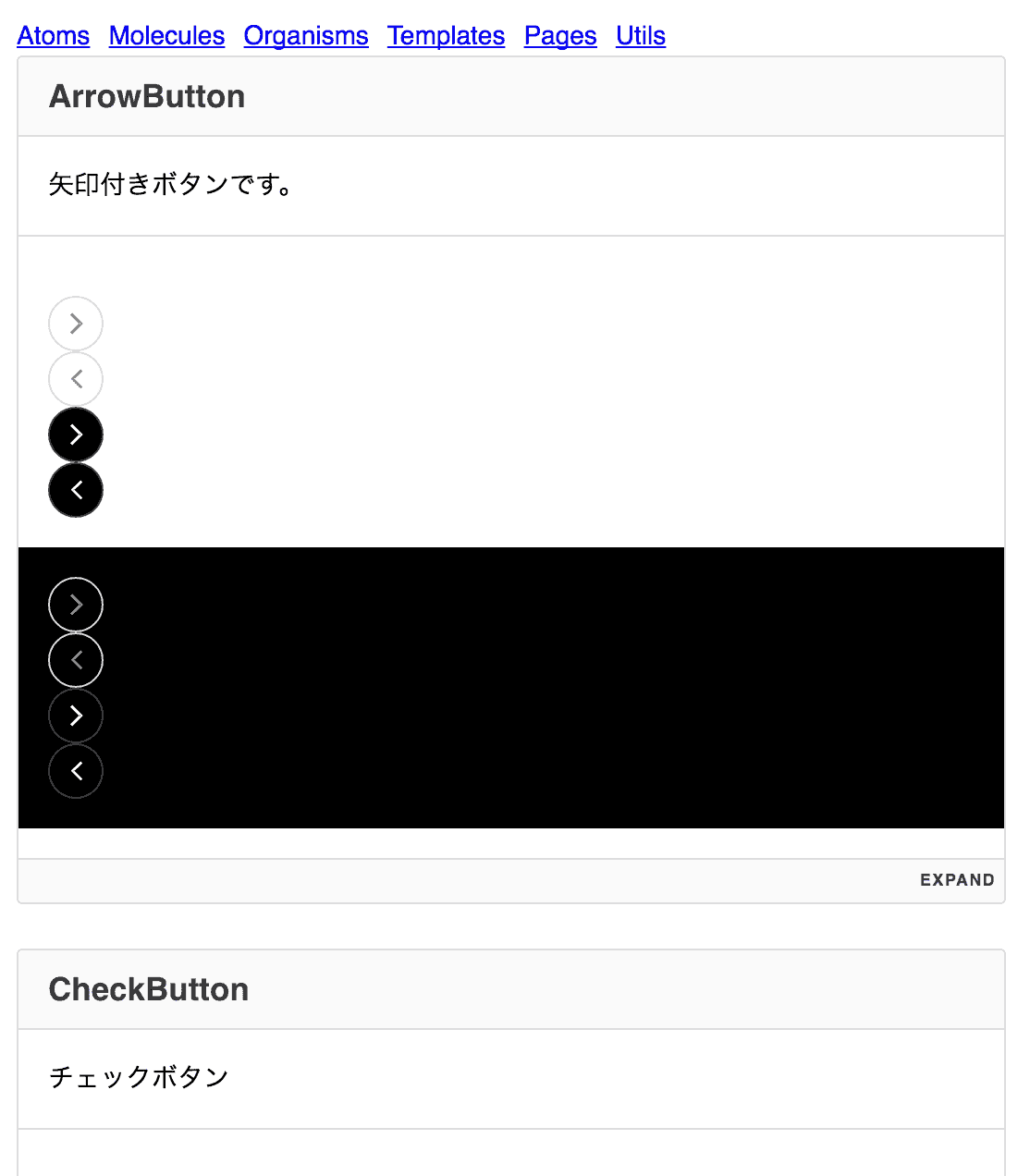
現在開発担当している AbemaTV で、昨年末にパナソニックさんのスマートテレビ VIERA 向けにアプリケーションをリリースしました。AbemaTV リモコンボタンで AbemaTV にアクセスできます。今回このアプリケーションの UI を開発するにあたって、新しいデザインワークフローを導入しました。
本記事では、 Story-Assured Design というデザインワークフローを、現在プロダクト開発で直面しているデザインの課題とともに紹介します。
Story-Assured Design とは?
Story-Assured Design はその名前が示しているように、ユーザーストーリーを保証することを目的とした UI デザインのワークフローです。UI デザインを3つのステップに分けて行います。
- ストーリーデザイン
- デザインの構造化
- 視覚情報デザイン
一番重要なユーザーストーリーのデザインから始めて、それを保証するようにフローを進めていきます。大袈裟な名前が付いていますが、奇抜なことをやっているわけではなく、デザインする上でやった方が良いことを明示的なデザイン工程として分割しているだけです。しかし、分割することによって規模が大きくなってきたサービスが抱えがちなデザインに関する問題にアプローチすることができます。逆に言えば、規模が小さく収まるサービスやプロダクトを作り上げるだけであれば、目的に対して複雑な手順を取り過ぎるかもしれません。
今回このワークフローで1つのプロダクトの初期リリースを終えてみて、兼ねてから課題に思っていたことが解決できたので、それを共有したいと思います。
デザインに関する話を書いていますが、このプロジェクトでの私の役回りはテックリードで、プロダクトのオーナーシップを持ったエンジニアとして開発の進行、エンジニアリング、デザイン、ビジネスとの調整を行ううちに得た副産物になります。
このデザインワークフローで解決したかった課題
Story-Assured Design の実践方法の説明に入る前に、まずこのデザインワークフローで解決しようとした課題と導入の経緯について触れたいと思います。
従来のデザインのやり方でもアプリケーションを作ることはできますが、将来的にデザインを改善し続けることを考えると下記4点のことが課題でした。
- デザインを定量・定性的に評価することが難しい
- デザイン作業を分担することが難しい
- 未完成のデザインに対して早期からユーザビリティテストすることが難しい
- デザインの負債によりいづれ改善速度低下してしまう
逆にこれら4つの課題が解決できれば、組織が大きくなっても、プロダクトの年齢が上がっても、自分たちの力でデザインを1歩ずつ確実に前に進化させることができるのではないかと思います。そして、この課題解決をデザイナーやチームのメンバーの力量に左右されることなく、仕組みによって大部分を解決できればと思い、ワークフロー化しました。
課題1:デザインを定量・定性的に評価したい
プロダクトが飯の種になっている以上、どんなデザインが良くて、どんなデザインが悪いのか、アプリケーションの開発に携わる人なら誰でも多かれ少なかれ関心があるテーマだと思います。目的や文脈が異なればデザインの善し悪しもそれに応じて変わりますが、それでもデザイン1つで売り上げが変わったり、ユーザーの使用頻度に影響が出てしまったり、プロダクトの寿命が左右されてしまうことを思うと、自分たちのプロダクトのデザインが間違いなく良い方向に進んでいることを確信したいと思っています。
しかし、デザインを評価することは難しいです。誰もが目で見て触る部分なので、簡単に意見できたりしますが、1ユーザーとしての意見を言うことはできても、プロダクトもしくはサービスにとっての正解は誰も知らないことがほとんどです。それに比べるとエンジニアリングは評価しやすいと感じます。ソフトウェアエンジニアリングであれば、実際の処理時間やパフォーマンスを計測して評価したり、コードの設計が拡張しやすくなっているかを評価したり、など多少の好みや比重の置き方に違いはあっても、何となくみんなが共通で考えている正解が存在します。
デザインの「良い」を定義したい
デザインにもみんなが共通で考えることができる正解が存在すればいいなあ、とかねてから思っていました。そうすれば良いデザインをちゃんと評価できます。
デザインコンサルタントの長谷川恭久氏のブログ記事「デザインシステムの最初の一歩として原則を作る理由」で「自分たちにとっての良いって何だっけ?」を考えることについて触れられています。この記事の中で
お互いが考える『良い』をぶつけ合う
という一文がありますが、デザインをみんなで考えたり、振り返ったり、評価しようとすると、まさに「お互いが考える『良い』をぶつけ合う」状態になりがちだなと思います。
Story-Assured Design では3つのステップに分けて UI デザインを進めますが、1つ1つのステップにおいてチームで共有する『良い』が定義されます。これにより、少なくとも「お互いが考える『良い』をぶつけ合う」状態は避けることができました。
課題2:デザイン作業を分担したい
何人かのデザイナーと一緒に仕事していると、当然のことですが、デザイナーにもいろいろなタイプの人がいることが分かります。あるデザイナーはグラフィックが得意だったり、情報整理が得意だったり、サービスのブランディングが得意だったり、アイデアの引き出しが多かったり、分析が得意だったり、いろいろな人がいます。でも、デザインの仕事にはこういったこと全てが求められます。
デザインの不得意領域の負荷分散
どのプロジェクトでもアサインされるデザイナーの数は多いわけではないので、場合によっては担当デザイナーが不得意な領域でもデザイン作業としてお願いしなければならない場合があります。今までさまざまなチームでアプリケーションを開発してきましたが、どのチームでもデザイン作業はデザイナーがやるものでした。でも、明らかに情報整理が苦手なデザイナーは、ブレインストーミングで好き勝手に出たアイデアを整理する作業に苦しみますし、やっぱり何度もやり直しを繰り返すことになります。こういうとても非効率に感じる場面もたくさんありました。
そういうとき、苦手な領域のデザイン作業をデザイナー以外でも担当できたり、時にはチーム全員の知恵を借りてデザインに関する課題を解決できたらいいのに、と思います。そこで、Story-Assured Design では、デザイン作業のステップを分割することで分担しやすくします。
課題3:早期からユーザビリティを検証したい
私が経験してきたプロジェクトでは、ユーザビリティの本格的な検証は開発終盤に行われることが多かったです。デザインがある程度プロダクトに実装されてからでないとテストしづらかったからです。早期にユーザビリティを検証する方法としては、ペーパープロトタイピングなど方法はあるのですが、やはり実機で早期に検証できる方が確実です。最近だと、ペーパープロトタイピング自体がしづらい特性のプロダクトもあります。
また、開発経験がない分野だと、ある程度のベストプラクティスさえもイメージできないので、実機で確認するまで気付かないデザインの落とし穴もあります。
新分野のアプリケーション開発は難しい
現在私は未着手のデバイスを開拓することをミッションに持った開発をやっています。未着手なので、当然その領域の知見はほとんどない案件ばかりです。未着手といっても、世の中的に未着手というわけではなく、あくまでも自分たちにとって未着手なので、もちろん調べれば知見に巡り合えることもあります。ただ、経験値がない状態では知見の適用するにも見様見真似感が否めません。基本的に経験がない分野でのプロダクトデザインは難易度が高いと感じます。
本記事のプロジェクト以前に、今年始めに AbemaTV VR という AbemaTV の Google Daydream 版アプリの開発を担当しました。そのプロジェクトでは私はテクニカルディレクターという立ち位置でしたが、開発を進める中で、同じアプリケーションでもスマホや PC アプリと同じ感覚でデザインしていては全く使いやすくなっていかないことを痛感しました。このあたりの奮闘は当時の担当デザイナーの解説記事にもあります。
AbemaTV VR の開発では結果的にリリース日を少し延期して UI デザインの品質を上げるという決断に至りました。知見がない新しい分野の開発にも関わらず、私たちは技術的な課題ばかりに目がいき、完全に UI や体験に関するデザインをなめていたために発生した失敗でした。
過去の一見似ている経験を過信したことを反省しました。普通に考えれば、自分たちはスマホと PC 向けのアプリケーションのデザイン経験しかないのだから、それ以外のデバイス向けにプロダクトを開発するときは初心にかえってデザインするのが正しい姿です。開発の早いタイミングからプロダクトを触り始められるデザインワークフローにしてデザインの問題点を早々に発見することが大事だと痛感しました。
新分野ではデザイナーもデザイン未経験
この VR プロジェクトでは、新規分野ではデザイナーもデザイン未経験だということを忘れてはいけない、ということも痛感しています。開発初期はちゃんとしたデザイナーにデザインを任せれば、デザインはなんとかなるだろうと思ってしまっていました。
VR のプロジェクトでは、このデザイナーはさまざまな試行錯誤を繰り返し、最後まで諦めずに UI の品質を追い求めました。最終的に良い品質のものができることに何の疑問もありませんでしたが、そんな彼でも身近な人物にユーザーテストをしてその反応を見るまでは VR 特有の穴に気づくことは難しいものでした。
VR 上の UI 要素は画面内に入っていてもユーザーが気付かないことがあります。VR の場合は焦点が合っている対象物の臨場感が大きいため、それ以外の要素の存在感が雑音になりやすいのです。
そのため、たとえばサイドメニューのような普段は使わないため閉じておきたい要素をユーザーに開かせる場合、画面の端っこの方に開くボタンを配置しても想定以上にユーザーが気付かないことに後になって気付きます。スマホアプリの場合だと画面右上端にハンバーガーメニューがあれば、気付いてもらえると思います。その感覚からすると、何となく VR 画面でもデザインカンプ段階だと良いデザインに思えてしまいます。(しかし、実際に実機で見ると全然気付かないのです。)
リアルな感触による早期デザイン改善
それらの経験を踏まえて、新規分野の場合は特にデザインに対してしっかりと早めに説得力があるフィードバックを得られることが大事だと実感しました。プロダクトのリリース前であれば、一番説得力があるフィードバックは、やはりデザインに対する自分たちの直接的な感触です。
検証しやすいデザイン要素を分離する
そこでユーザビリティに関わる要素の中でも検証しやすい部分だけ分離してデザインし、先に実装することで、プロダクト開発の流れの中であまり寄り道することなくプロトタイプを作ることができます。そして、プロトタイプとして自分たちで触り検証しながらそのまま改善していくとプロダクトに昇華できるので、開発におけるプロトタイプ開発工数が最小にすることができます。
Story-Assured Design ではユーザーストーリーを構成する UI 要素を先にデザインすることで、ストーリーを開発フェーズの早期から検証しながら、そのままシームレスにプロダクトへと昇華していきます。
課題4:デザインの負債による改善速度低下を防ぎたい
解決したい課題の最後になりますが、「デザインの負債による改善速度低下を防ぎたい」、個人的にデザインフローを変えた一番の理由はこれでした。
サービス開局3年が経過して感じていること
現在私が担当している AbemaTV というサービスは開局3年が経とうとしています。サイバーエージェントに入社してから、どちらかというと新規プロジェクトの立ち上げを多く担当してきたので、リリース後に3年も同じサービスの運用開発していること自体が初めての体験です。以前は正直3年も同じサービスを担当していたら飽きそうだなと思ってましたが、意外なことに飽きていません。新規開発では経験しなかった2種類の課題に挑戦できるからだと思います。
1つ目はサービス自体が成長し続けていることで生まれた課題に挑戦できる点です。私個人の話でいうと、サービスリリース当初は AbemaTV Web 版 を立ち上げていましたが、組織的な動画技術力進化が課題になり、半年渡米して動画技術研究し、帰国後は未着手デバイス開拓と動画再生技術のエンジニアリングに軸足を置いて技術的な挑戦を続けられています。ほかにも動画技術エバンジェリスト※1 ※2 のような立場で変則的なアプローチでの技術的な挑戦ができるのも、サービスが成長し続けているおかげだと思います。
2つ目は長く運用開発しなければ直面できなかったと思える課題に挑戦できているからだと思っています。そんな課題の1つに「 デザインの負債 」という概念があります。私自身は、新規プロジェクトの立ち上げをメインにやっているときは、ほとんど意識しなかった概念です。というのも、デザインの負債は変更し続けることを前提としたプロダクトのデザインでしか生まれない概念だからです。
デザインの負債
開発に携っている人なら「負債」という言葉を普段から耳にすると思います。私もエンジニアなので負債といえば「技術的負債」という言葉が真っ先に頭に浮かびます。技術的負債といえば、いきあたりばったりのソフトウェアアーキテクチャによって既存コードに対する機能追加や変更のコストが高くなることを指しますが、「デザインの負債」は簡単に言えば、そのデザイン版です。いきあたりばったりのデザイン改修の繰り返しによって将来的なデザイン変更がしづらくなっていくことを指します。
私がデザインの負債を明確に意識し始めたのは Google のプロダクトデザイナーである Austin Knight 氏の『 Design Debt 』という記事を読んでからでした。この記事で、デザインの負債とは、新しいユーザー体験のためのデザインが既存デザインに統合できなくなってしまう状態のことだと言っています。
負債を持つことは誰しも好まざるところですが、良いデザインを生むためには直感ドリブンとデータドリブン両方のデザイン手法が必要です。直感ドリブンだけでは目の前のコンテキストや人の瞬間の感覚に左右されすぎますし、データ・ドリブンだけでは現状に対する改善はできても、まだ現実に存在していないものはデザインできません。両方をうまく組み合わせてデザインする必要がありますが、一見相反する性質の2つを組み合わせるので、どうしてもデザイン的には矛盾がある瞬間が生じてしています。
このような矛盾は明らかに「デザインの負債」と呼べるものですが、負債は返済するものなので、放っておいて大きくなる前に返済するようにする必要があります。Austin 氏は小さなループで負債を生んで、大きなループで負債を返済するといいよ、とも言っています。
デザインの負債に気づきたい
それで当然ながら、AbemaTV もデザインの改修を繰り返しているので、いろんなデザインの負債があります。小さなループで負債を生んで、大きなループで返済するといっても、返済するためには負債に明確に気づく必要があります。
デザインの負債要因1「複数の平行プロジェクト」
サービスの成長速度を加速するためには、複数のプロジェクトが平行して走る必要があります。プロジェクトはそれぞれ自分たちが達成すべきゴールを持っているので、デザインの最適解もそれに応じて変わります。デザインは目に見えて触れることができるという特性上、ゴールが異なるプロジェクトからは矛盾するフィードバックをもらうこともあります。あるプロジェクトからは良いと言われたデザインが別のプロジェクトからは悪いと評価されたりです。全て折り合いをつけようとすればデザイン上に何かしら無理が生じ、それが後でデザインの負債としてのしかかります。また、デザイナー自身が特定のプロジェクトにコミットする体制を取っている場合は、プロジェクトの文脈に最適化されたデザインになってしまうリスクもあります。
どのプロジェクトも一番目立つところに自分のプロジェクトの数字を上げるための導線を配置したいと思うでしょうし、全部のプロジェクトの導線を目立つところに置けばレイアウトの優先順位は崩壊し、ユーザー体験を激しく損ねるでしょう。たとえプロジェクトに優先度が付いていたとしても、既存のデザインはそのために作られたわけではないので、その優先度を表現できるように変更されるためには大きな工数がかかります。さらに悪いことには、複数のプロジェクトが平行して走っているときは大抵の場合、全てのプロジェクトの優先度が「S :最高」だったりします。
それでもプロダクトの数が1つであれば良いですが、インターネット上でサービスを展開するのであれば、iOS、Android、Web などメジャーどころの複数の媒体にプロダクトを展開していることが一般的です。スモールスタートで Android だけ先にリリースしていたり、ある技術のエンジニアが他方に比べて不足している場合など、さまざまな理由でプロダクトごとに成熟度が違う場合は先行して特定のプロダクトにだけプロジェクトが走ったりすることもあります。すると、プロジェクトを実現するためのデザインがそのプロダクトに最適化されてしまい、追いかけてリリースするプロダクトにデザインが適用できなかったり、適用しても不自然さが残り負債になるでしょう。
複数のプロダクトに複数のプロジェクトが走っている状況では、いわゆるリードデザイナーが人力で全てのデザインを見て品質を担保することは不可能です。組織体制の変更やワークフローの工夫など仕組みとしての解決が必要になります。
デザインの負債要因2「短納期」
複数の平行プロジェクトが走っているということは、1つ1つのプロジェクトのデザインにかけられる絶対的な時間が少なくなるということです。デザインは開発の最初のプロセスなので今後の開発に大きく影響するような決断を迫られることが多いと思いますが、ここに時間がかけられないということはプロジェクトとプロダクトの品質に関わる判断をミスるリスクが大きくなるということです。
「あのときもう少し時間をかけて考えていれば。。」と思うことは誰しもあることだと思います。とはいえ、時間をかけることが許されない状況は変わりません。そもそもデザインは決断の連続なので、プロジェクトの度に考えて判断していてはどれだけ時間があっても足りなくなります。プロジェクトの度に考えなくてもいいように、明文化された判断基準が共有されていると、何を考慮しなくてもいけなくて何は考慮しなくてもいいのか迷うポイントが減り、判断をミスるリスクも小さくなります。
デザインの負債要因3「積み重ねられたコンテキスト」
デザインは複数の問題を解決する仕事です。改善を積み重ねていると、目の前にある課題のコンテキストに左右されすぎて、解決しようとしているもの以外の問題が見えなくなってしまうことがあります。
特に好ましくないのが、1つの問題の解決した副作用でこれまで解決してきた問題が再発することです。長くプロダクトを改善していると、1つの画面デザインはさまざまな問題を解決した後の絶妙なバランスで構成されています。プロダクトの年齢が高くなればなる程デザインの難易度が上がっていきます。長く担当しているデザイナーでも大昔に解決した問題を忘れてしまうこともあるので、新しくジョインしたデザイナーにこの何層にも積み重ねられたコンテキストを読み解くことを期待することは無謀なことです。
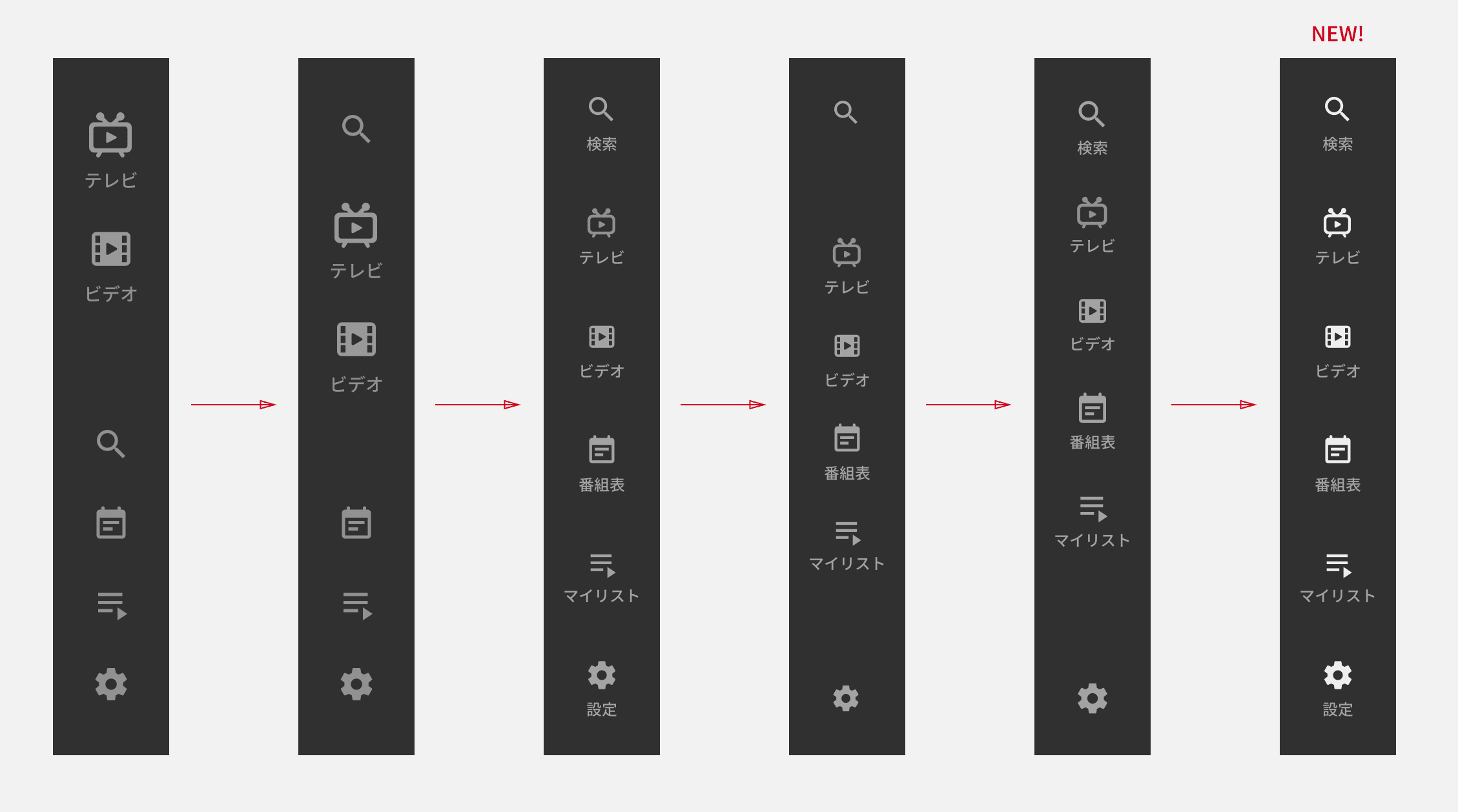
たとえば、上図のようなあるグローバルナビゲーションのデザイン改善の履歴では、「サービスのメイン機能を目立たせたい」、「推したい機能をよりアクセスしやすい距離に配置したい」、「文字文字しい見た目をスッキリさせたい」、「アイテムを優先度によるグルーピングをしたい」、「配置のバランスを整えたい」などの課題が発見され、その都度コンテキストが積み重ねられています。しかし、このコンテキストは Slack 上で展開された議論を遡ってみれば分かるのですが、Sketch のデザインデータ上から読み取ることは困難です。積み重ねたコンテキストを忘れてデザインに修正を加えた場合、解決された問題が再発する可能性もあります。
改善の繰り返しによってコンテキストが積み重なったとしても、今までデザインが解決しようとした問題を振り返ることができるようになっていれば、目の前の改善案によって過去に解決した特定の問題がデグレーションを引き起していないかを確認することができます。
デザインの負債要因4「ここでしか使っていないパターンの導入」
デザインはパターンが統一されている方がユーザーにとっては使い方に迷うことが少なくなります。しかし、あるデザインパターンを導入するとき、特定の条件の画面だとそのデザインが破綻してしまうリスクがあるときあります。
そんなとき「今このデザインはここでしか使ってないから大丈夫」と導入すると、近い将来高い確率で負債になります。導入のタイミングでは、破綻したときにデザインを見直すことにして一旦これでいこうと思ってしまうことも多いですが、その後の改善でそのデザインの上にもいくつもコンテキストが積み重ねられていきます。そうなるとそのデザイン修正は積み重ねられた複数の問題を一気に解決しないとデグレーションになってしまう難易度が高いものになります。多くの場合は「ここのデザインを修正するのはデメリットが多すぎるからやめよう」ということになります。その場所のデザインを修正できんなくても、解決しなければならない問題は残り続けるので、別のアプローチでのデザイン修正で解決を試みるのですが、よほど筋が良いアプローチでないと無理が生じて更にデザインの負債が積み上がることも少なくありません。
この場合の「ここでしか使っていないデザイン」は「ここでしか使えないデザイン」なので、その時点でも負債です。少なくともその場の人間がパッと思い付くような条件で破綻するようなデザインは、将来的にも導入される場所になる可能性が高いので導入は避けるべきだと思います。
大抵の場合、1つの問題を解決する手段はいくつもあります。しかし、コンテキストが重なっていくとさまざまな制限により取れる手段が少なくなっていきます。長くサービスを運用するのであれば、同じ問題を解決するにしても選択肢ができるだけ減らないような手段を選ぶ必要があります。それができるのは選択肢が多いうちだけです。
デザインの負債要因5「暗黙の知見化」
運用期間が長くなると開発メンバーも入れ替わります。私も AbemaTV 立ち上げ時にいた開発チームにはもういませんし、ほかのエンジニアやデザイナーも入れ替わっています。入れ替わってもチームに同じ職種のメンバーが複数いる場合は、順々に入れ替わるので、仮に明文化されていない知見が存在しても、一緒に開発している間に受け継がれたりします。
最近のプロダクト開発ではエンジニアは複数人開発していることが多く、総入れ替えは発生しづらかったので、これにより知見の暗黙化が防がれて助かっている部分がありました。それに対して、デザイナーの方が人数が少なく、基本的に1プロダクト1デザイナーになりがちでした。必然的にデザイナー総入れ替えパターンは発生しやすくなっていました。
そうすると、前のデザイナーの意図が正しく受け継がれないことも多く発生します。「このデザイン、何でこうなってるんだっけ?」と一番長くいるデザイナーに尋ねることも多いです。尋ねる分にはまだいいですが、「既存のデザインがそうなっていたので合わせました」と意図が理解されないままデザインが継承されることもあります。もし元々のデザインの意図が適さないものだったら、継承先のデザインはどこかのタイミングで思わぬ形で矛盾を露呈することになります。
デザインの負債要因6「統一されていないデザインデータ構造」
デザインはデータで管理されることが多いと思います。AbemaTV も Sketch のデータとして管理しています。データは使いやすくするために用途に応じて整理されると思いますが、チームで整理方法の基準が決まっていなければ、整理した人によってデータの構造はバラバラになるでしょう。AbemaTV も初期は作業速度重視でプロダクトことで担当デザイナーが決まっていたので、プロダクトごとにデザインデータの構造はバラバラです。
プロダクトごとにデザイナーが固定の場合はこの場合でも最速だと思いますが、デザイナーが変われば効率は一気に落ちるリスクがあります。サービスのフェーズが変わると、プロジェクトごとに最高の成果にコミットできる組織構造にするためにプロジェクトごとにデザイナーをアサインするように変更したくなる場合もあります。しかし、プロダクト間でデザインデータの構造が統一されていなければ作業効率が下がるため、組織構造にチームがついていけなくなります。
デザインの負債要因7「デザインの評価ができない」
デザインをリリースした後そのデザインの評価ができないこともデザインの負債の要因です。新しいデザインに対するユーザーからのフィードバックをリリースした後すぐにもらえるのは稀だと思います。大体の場合はフィードバックは遅れて開発者に届くものです。でもそうすると、リリースしたデザインが良いのか悪いのか分からない状態で次の開発に進むことになります。
遅れてフィードバックをもらえたとしても、矛盾するフィードバックやターゲットユーザーではない人からのフィードバックもあったりします。フィードバックを鵜呑みにしてもプロダクトデザインが改善されるとは限りません。
こういった状況でデザインの変更を積み重ねていくと、時間差で届いたフィードバックを効率的に取り入れることができなかったり、取り入れるべきでないフィードバックを間違って入れてしまう可能性があります。そうなればデザインの負債です。
ユーザーの直接的なフィードバック以外にも、Google Analytics などの解析ツールを使うことでファクト(事実)として自分たちのデザインを評価することはできます。しかも、ファクトはリリース後すぐに数字などの変化により収集することができます。ただし、ファクトが収集できるのは、ファクトが収集できるように考慮されたデザインのみです。解析することを何も考慮されていないデザインから正しいファクトを取り出すのはものすごく難しいです。
積極的に直接的なフィードバックを取得する方法としては「ユーザーテスト」などの手段もあります。しかし、ユーザーテストは解析などにより収集されたファクトがある前提で、そのファクトになっている理由を調査する方法であって、ファクト自体を収集する方法としては適していません。
「A/B テスト」などの手段でデザインを定量的に評価することもできますが、これもテスト対象のデザインがきちんと分離されていないと、正しい結果を導くことは困難です。
カリスマ的なデザイナーが全てのデザインを評価する、ということもできます。しかし、これはスケールしないので破綻も時間の問題です。
デザインを評価するためには、評価できるようにデザインすることが必要になります。エンジニアがテスタブルなコードを書くようにするのと同じです。
デザインの負債要因8「デザイン改善の優先度が測れない」
前述の「デザインの評価ができない」に似ていますが、デザイン改善の優先度が測れないためにデザインの改善速度が下がることがあります。リリース後もプロダクトは改善のために更新され続けますが、デザイン改善以外にもプロダクトの改善要素はたくさんあります。事業インパクトが大きい追加機能やプロモーションイベント、実装やメンテナンス効率を上げるためのリファクタリングやパフォーマンスチューニング、さまざまな種類の改善タスクがある中でデザイン改善に関するタスクが優先度でほかのタスクに負けて改善速度が下がってしまうのです。
事業インパクトが大きいことが分かっている追加機能やプロモーションイベントは優先度の高さが分かりやすいですが、リファクタリングやデザイン改善といった一見効果が目に見えずらい改善タスクは気にしている本人たち以外にはその優先度が理解できません。コードのリファクタリングなどはエンジニアが気にしていることなのでエンジニア自身が作業の合間を見て実施したりもしますが、デザイン改善はデザイナーが気にしていてもエンジニアが実装しなければプロダクトに反映されません。デザイン改善の優先度が気になっている本人以外にその優先度を伝えることができなければ、ほかのタスクの優先度に永遠に勝てなくなることもあります。
デザインの評価ができていれば、デザイン改善の優先度は高くなるかもしれません。しかし、既に評価が高いことが分かっていたら、逆に「これ以上改善することもない」と思われてしまうかもしれません。デザイン改善の優先度を伝えるには、改善の重要度が伝わるようにしなければいけません。
課題を解決するためのデザインフロー
これらのデザイン課題を解決するために Story-Assured Design では下記6つのことを行っています。
- 定量評価するためにデザインに KPI を設定する
- デザイン作業を分担できるように作業工程を分割する
- 事業利益とユーザー満足度各々に対するデザインを評価する工程を入れる
- 早期にユーザーテストできるようにモック開発までのデザイン工程を明確に分割する
- デザインの負債を意識するためにユーザー・ストーリーを保証するデザイン工程を入れる
- デザイン改善の優先度が伝わるように「Why? How? What?」の順で成果物を作る
デザインに KPI を設定する
今回のプロジェクトで幸運だったのは、プロジェクト開始時に「 とにかくリモコンでボタンを押す回数を少なくしてほしい 」と明確に要望されたことでした。
皆さんもテレビを使ったことがあると思うのでイメージしてもらえると思いますが、多くのテレビのリモコンにはタッチパッドのようなインターフェースはないので、十字キーを押して操作します。画面上に見えていても端の方にある番組を選択するためには何度も同じ方向の十字キーを押すことになります。
ユーザーが少ないリモコン・ボタン操作で自分がやりたいことができるなら、それだけでもかなり使いやすい UI と言えるはずです。そこで、「プロダクトを使いやすいものにする」という KGI(Key Goal Indicator)に対して、「リモコンでボタンを押す回数」という KPI(Key Performance Indicator)を設定し、「リモコンでボタンを押す回数を各画面3回以内」になるように目指しました。
KPI を設定したことにより、チームの誰もが同じ目線でデザインを評価できるようになりました。
作業工程を分割する
デザイン作業の種類に得意・不得意がある場合でも作業自体を分担できるように、Story-Assured Design ではデザインの作業工程を分割します。冒頭に述べた通り3ステップに分割しました。
アプリケーションのデザイン作業は、ユーザーに意図した動作をしてもらいやすいストーリーを考え、そのストーリーを画面における情報要素の配置(レイアウト)を考え、魅力的な見た目を作り上げることをしなくてはいけません。しかし、そのうち、グラフィック能力に長けていないと作業できないのは、最後の魅力的な見た目を作り上げる工程で、そのほかの工程は意外とデザイナー以外も作業に参加できます。ただ、これらの一連の作業をデザインカンプの上で、一人のデザイナーが一気にやってしまうとチームのほかのメンバーが参加するのが難しくなってしまいます。
今回のプロジェクトでは、それぞれのデザイン工程でチーム全員でデザインを考え、レビューをし、時には作業自体をデザイナー以外にも分担しました。特にユーザーストーリーをデザインする作業はディレクターの方が得意なことも多く、その部分はデザイナーとディレクターが分担してデザイン作業しました。
デザイン作業の細分化によりチーム全体のデザインへの理解度が上がる
作業工程を分割して細分化したことにより、副産物としてデザインに対するチームの理解度が上がりました。後述しますが、作業工程自体が「Why? How? What?」の順で成果物を作るように分割されています。これによりなぜこのデザインの変更が重要なのかがチームメンバー全員に伝わりやすくなる効果もあります。
事業利益に貢献するデザインとユーザー満足度に貢献するデザインを各々評価する
従来のデザインワークフローでは、事業利益を上げるためのデザインとユーザー満足度を上げるためのデザインを一緒にレビューしていました。しかし、この形式だとレビュースコープが広すぎるため、レビューワーによって見ることができる問題に差ができてしまいます。レビューワーによってはユーザー体験に関わる問題は指摘できるけど、事業利益に関わる問題を指摘できない、などです。議論に発展しても収拾がつかないことも多く、最終的に決裁権を持つ人や声が大きな人の好みで方向性が決定してしまうリスクもあるでしょう。
当然ですが、どれだけユーザー満足度が高くても事業利益が上がらなければ、サービスは潰れます。逆にどれだけ短期の事業利益が上がっていてもユーザーが満足していないサービスはいづれユーザーが離れていくので、やはりサービスは潰れます。この両者を高い品質で成立させるようにデザインすることは難しいですが、サービスが大きく成長しながら長く生き残るためには必須です。
そこで Story-Assured Design では初期工程ではより事業利益に関わる要素にできるだけスコープを絞りデザインを評価し、後の工程でユーザー満足度に関わる要素に絞ってデザインを評価します。
モック実装に必要なデザイン工程を分離する
アジャイル開発の基本は「不確実性を取り除くこと」です。どんなに初期にデザインレビューをしても、考えたデザインは人の頭の中でシミュレーションされているだけなので多分に不確実性を含んでいます。しかし、実機でデザインに触れることができるようになると、不確実な要素は一気に具体的な体験として解消されます。それとともに具体的な課題も明らかになります。
不確実性をできる限り取り除くために、開発の早い段階からユーザビリティテストで評価できるようにモック実装に必要な要素から集中してデザインします。これによりプロダクトが完成に近い形になるかなり前から致命的なデザインの不具合を発見し、リリース前でも確実なデザインの改善を進めることができます。
ユーザー満足度を上げるモックドリブンデザイン
デザインにおいて特に不確実性が高いのは、ユーザー満足度に関わる要素だと思います。デザインされた細かな要素がユーザーの最終的な満足度を向上させます。理想を言えば、実装したデザインをさまざまなユースケースでテストしてからリリースしたいところですが、現実的には時間にも限りがあります。
Story-Assured Design では、事業利益に関わるベースデザインを作成した後は、モック実装しながらユーザー満足度を向上させるデザインを平行して進めます。これにより限られた時間内でできる限り不確実性を取り除いたデザインを実現します。
ユーザーストーリーを保証するデザイン工程を入れる
モックを作って、ユーザビリティを徐々にテストできるフェーズになると、具体的な改善案が出るようになります。このフェーズでは細かい改善案が多く出ます。細かいデザイン修正によってプロダクトのデザインはより洗練されていきます。
しかし、これら細かいデザイン修正は先述した直感的な改善案であったり、コンテキストに強く依存した改善案であることも多いため、目の前の気持ち悪さを改善した結果、最初にデザインしたユーザーストーリーに影響を与えてしまう場合もあります。更に悪いことに、この変更をテストするときは出した改善案が適用されていることをテストしがちなので、既存のユーザーストーリーがデグレードしてることに気付かないことも多いです。
「木を見て森を見ない」状態にならないように、変更が既存のデザイン構造に影響を与えていないかをテストする仕組みがあれば、デグレードは防ぐことができます。Story-Assured Design ではこの仕組みのためのデザイン工程があります。
デザインの成果物を「Why? How? What?」の順で作る
デザインは、考案され、実装され、リリースされたら初めてユーザーに届きます。これらの作業は1人では完結しません。複数の人の手を介することになります。あるデザインを考えたデザイナーはそのデザインの重要性を肌で感じていると思いますが、リリースまでに携わる人がその重要性が理解できるとは限りません。
ある機能をユーザーに届けるために全くデザインされていない状態ではリリースすることができないため、デザインの優先度は絶対的なものです。しかし、一度ある程度のデザインが実装されたりリリースされている場合は、改善するためのデザインの優先度はその重要度が考案者以外にも理解されていなければ下がります。そのため、ワークフローの途中で考案者が意図しない形で優先度が下げられてしまうリスクもあります。
デザイン改善の優先度を伝えやすく、リリースまでに携わるより多くの人を巻き込めるようなデザインワークフローであれば、そのリスクを下げることに貢献します。後述しますが、「Why? How? What?」の形式に沿って途中経過の成果物を残すことでデザイン改善の優先度をよりチーム全体で共有しやすくします。
3ステップのデザインワークフロー
こうしてできあがったデザインワークフローが Story-Assured Design です。冒頭にお話した通り3ステップで UI デザインを作っていきます。
- ストーリーデザイン
- デザインの構造化
- 視覚情報デザイン
Why? How? What?
先程、Story-Assured Design では「Why? How? What?」の順で成果物が作られると書きました。これは Simon Sinek 氏が TED の「How great leaders inspire action」というトークでも語っているゴールデンサークル理論です。この理論は人を動かすためには「Why? How? What?」の順に伝えることがとても重要だと言っています。Story-Assured Design の3ステップはまさに
- ストーリーデザインで Why を作る
- デザインの構造化で How を作る
- 視覚情報デザインが作られると What になる
というステップに呼応しています。
ステップ1:ストーリーデザイン
Story-Assured Design で一番重要なステップがストーリーデザインです。なので最初にデザインします。その名前の通り、ユーザーストーリーをデザインする工程です。先程のゴールデンサークル理論でいうところの Why をデザインする工程 です。
このステップでは、 画面ごとにユーザーに得てもらう情報とその情報を得たことによって起こすアクション をデザインします。
事業利益に繋がる情報とユーザーの行動をデザインする
ほとんどのサービスは何らかの形で事業利益を生み出すために提供されていると思います。ストーリーデザインでは、ユーザー満足度に直接関わる部分というより、事業利益に貢献する部分に比重を置いてデザインします。つまり、使ってもらうことで事業利益を生む出すアクションまでのストーリーをデザインするのです。どんな情報をユーザーに与えれば次の情報に繋がるアクションを起こし、最終的に事業利益に繋がる行動や習慣に導きます。
このステップでストーリーを確立させた上で、以降のステップでより満足度高くストーリーに沿ってもらえるようにデザインしていきます。
ストーリーデザインの成果物
デザインしたものがデザイナーの頭の中だけで完結してしまっては、このステップを分割した意味がなくなってしまいます。アウトプットとして管理しましょう。このステップのアウトプットは、次のようにワイヤーフレームにとても近いものが良いです。
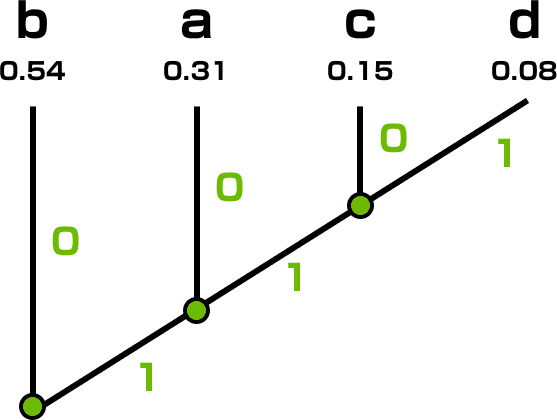
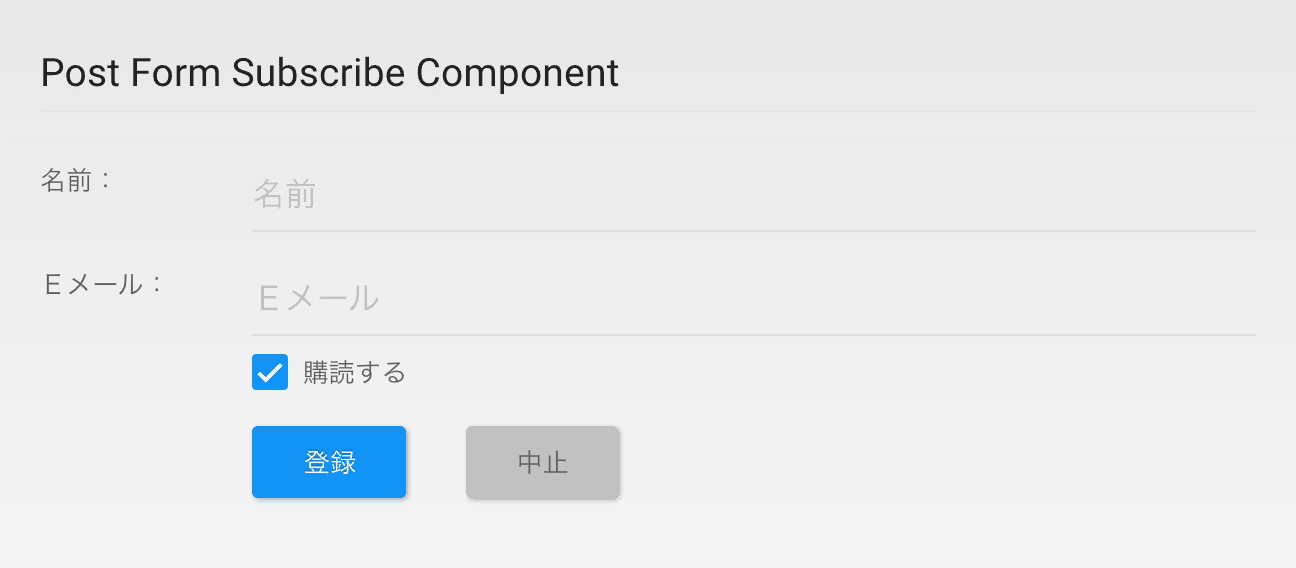
AbemaTV の開発ではデザインデータは Sketch で作られているので、今回のプロジェクトでもストーリーデザインのアウトプットは Sketch ファイルです。画面単位でワイヤーフレームのように画面に配置する要素をレイアウトしていくのですが、ユーザーストーリーが確実にデザインされていることを検証するために、このステップでは先述した KPI に対する数値も明記します。
例ではワイヤーフレーム図の下にユーザーストーリーに対するリモコンボタンの押下数を明記しています。これでデザインしたユーザーストーリーが KPI を達成しているかを確認します。

余談ですが、この KPI の表現方法は Google I/O 2018 でのセッション『An accessible process for inclusive design』からヒントを得ています。
とはいえ、画面にはいくつもの機能と選択肢があります。そこでストーリーデザインにおいてストーリーを作る手法としてオススメしたいのが、次に紹介する「プライマリーストーリーメソッド」です。
プライマリーストーリーメソッド
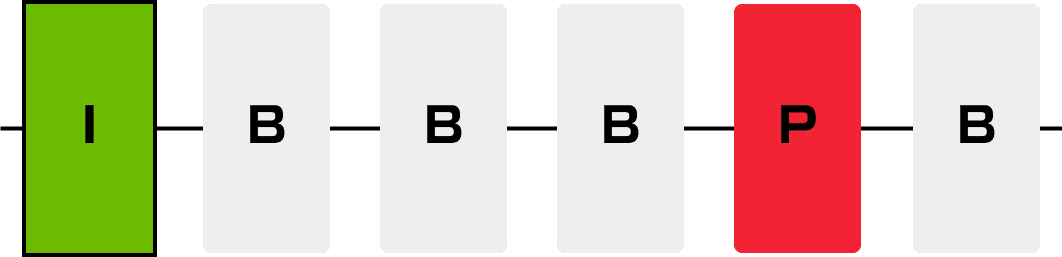
プライマリーストーリーメソッドは、1画面に1つだけ1番重要(プライマリー)なユーザーストーリーを設定することで、ストーリーデザインする手法です。とても単純明快なためチームメンバー全員が目線を合わせてデザインに参加することが容易なので新規プロダクトの初期デザインにオススメな手法です。

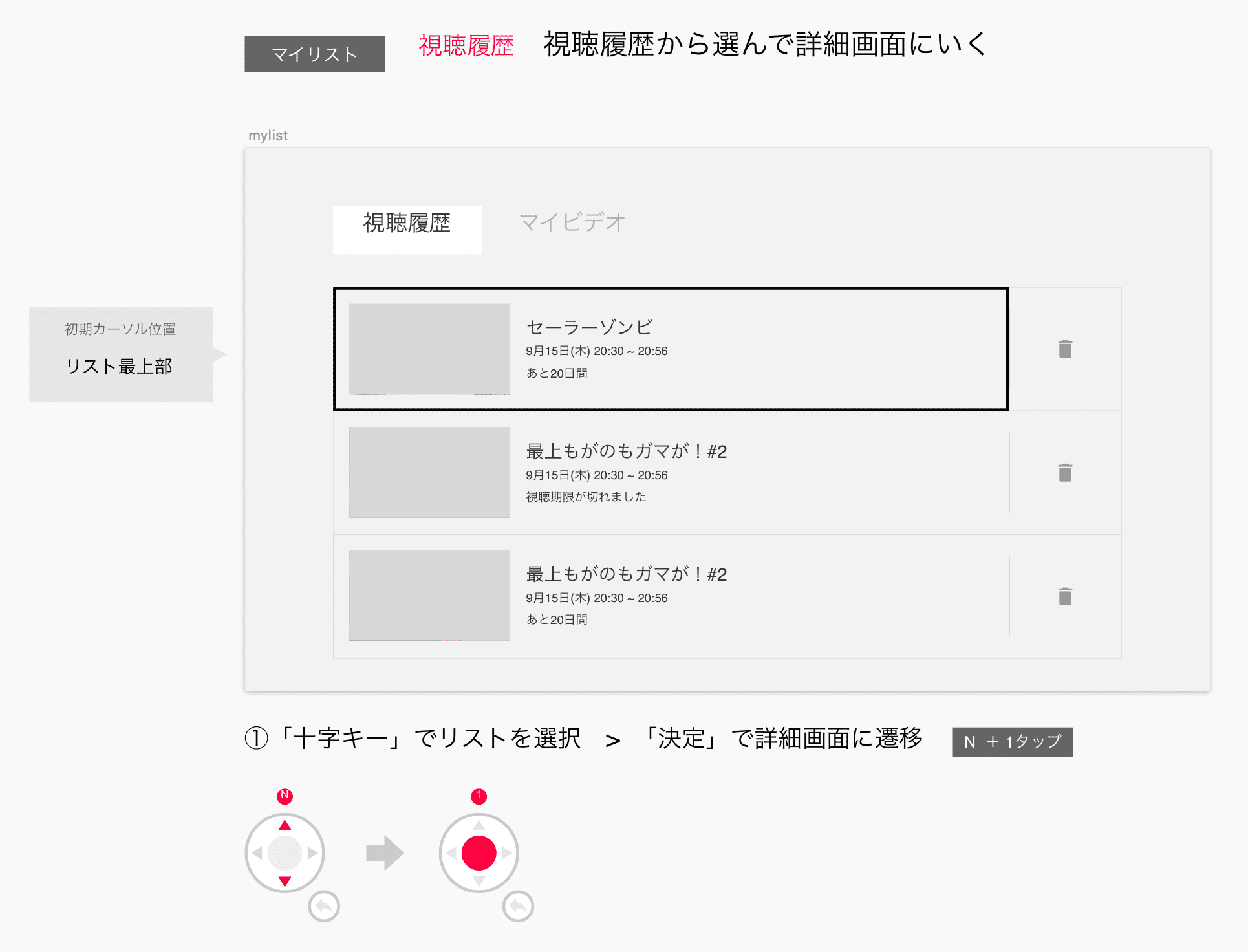
たとえば、この画面ではユーザーに過去に視聴した番組一覧を情報として表示して、そのうちの1つの詳細画面に遷移することをプライマリーストーリーに設定しています。この画面には視聴履歴とした記録されている番組を履歴から削除する機能やマイリストというお気に入りとして登録した番組を確認する機能を使うこともストーリーとして存在しますが、まずは1番多くのユーザーに良い体験を与えることができるストーリーを設定します。そしてそのストーリーに対して1番ボタン押下数が少ないカーソル移動経路をデザインします。
プライマリーストーリーメソッドは開発する側にとってもメリットがある手法ですが、ユーザーにとってもメリットがあります。ユーザーにやってもらいたいことが1画面に複数あるデザインは新規ユーザーを迷わせます。それでも、サービスを提供する側の心理としてはユーザーが離脱しないうちにできるだけいろいろなコンテンツや機能を知ってもらいたいので1画面に複数のストーリーを詰め込んでしまいがちです。プライマリーストーリーメソッドは1つの王道のストーリーを明確に優先することになるため、ユーザーは迷うことなくそのストーリーを選択することができます。
そして、ストーリーデザインの評価もしやすくなります。画面ごとに明確なストーリーがあるので、Google Analytics などを使ったユーザー行動計測との差分を確実に取ることができます。デザインの評価が難しいという話を先述しましたが、プライマリーストーリーメソッドによって、意図したデザインが数字として結果を出しているかがしっかり評価できます。
そして、意図したストーリーと違った結果が出たとしてもガッカリすることはないと考えています。ユーザーが想定と違う行動をしているのが事実だと確信できたら、自信を持って改善案を考えればいいのです。リリースする前のデザインはどんなものでも「ユーザーはそのように行動するはず」という仮定でしかありません。その仮定が肯定されればもちろん嬉しいですが、逆に完全に否定してくれれば、未練なく別アプローチでデザイン改善できます。
プライマリーストーリーがないと、画面においてユーザーに与えられた行動の選択肢が多すぎて、考えうる仮説も多くなりがちです。仮説が多いと考慮しなくてはいけないことが増え、ユーザーストーリーの設計も難しくなってしまいます。
余計な視覚情報を省いてストーリーに集中する
デザインを作成することになると、視覚的に美しく細部に拘ったデザインを作りがちです。しかし、ストーリーデザインではそれらの情報は邪魔になります。
Story-Assured Design では、チームメンバー全員でデザインを考えるので、作成したストーリーデザインも全員でレビューします。その際に視覚的に完成されたデザインを目の前にすると、色が見ずらさやレイアウト的な細かいズレなどの詳細に注意を奪われてしまい、ストーリー自体のデザインレビューに集中できなくなります。

ストーリーデザインでは、ユーザーがその画面で次のアクションを起こすために何の情報を得るように画面を構成していく必要があるかが分かるだけで十分です。情報がどのように伝えられるかがない方がレビューしやすくなります。
デザインレビューのスコープを狭める
ストーリーデザインという工程を明確に区切ることでデザインレビューのスコープを小さくすることができます。
現在は Abstract などのツールが一般的になってきて、デザイン工程の進捗を詳細に可視化することができます。
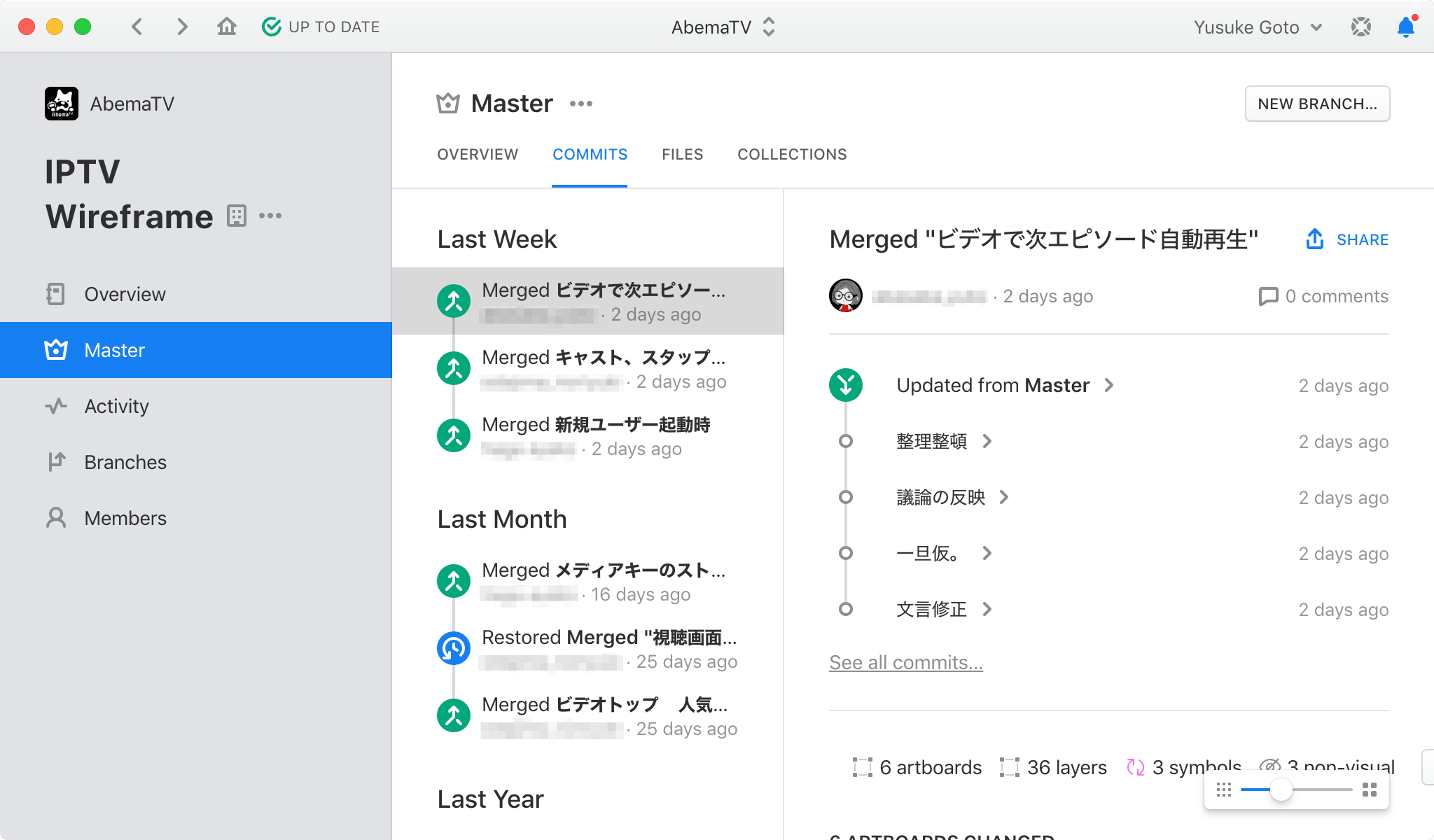
これによりエンジニアが Git や GitHub などを使ったときのように、プロダクトに対する変更をブランチ単位で可視化することができるようになりました。エンジニアがプロダクトに変更を加えたい場合、コードを変更してマージリクエストやプルリクエストすると思いますが、基本的にレビュースコープが小さくなるように変更範囲を工夫することでマージまでの時間は短かくすることができます。Abstract でも同様にプロダクトのデザインデータに変更を加えてマージするときにレビューリクエストすることができます。このときのデザインレビューのスコープをストーリーに限定すれば、同様にマージまでの時間が短かくなります。
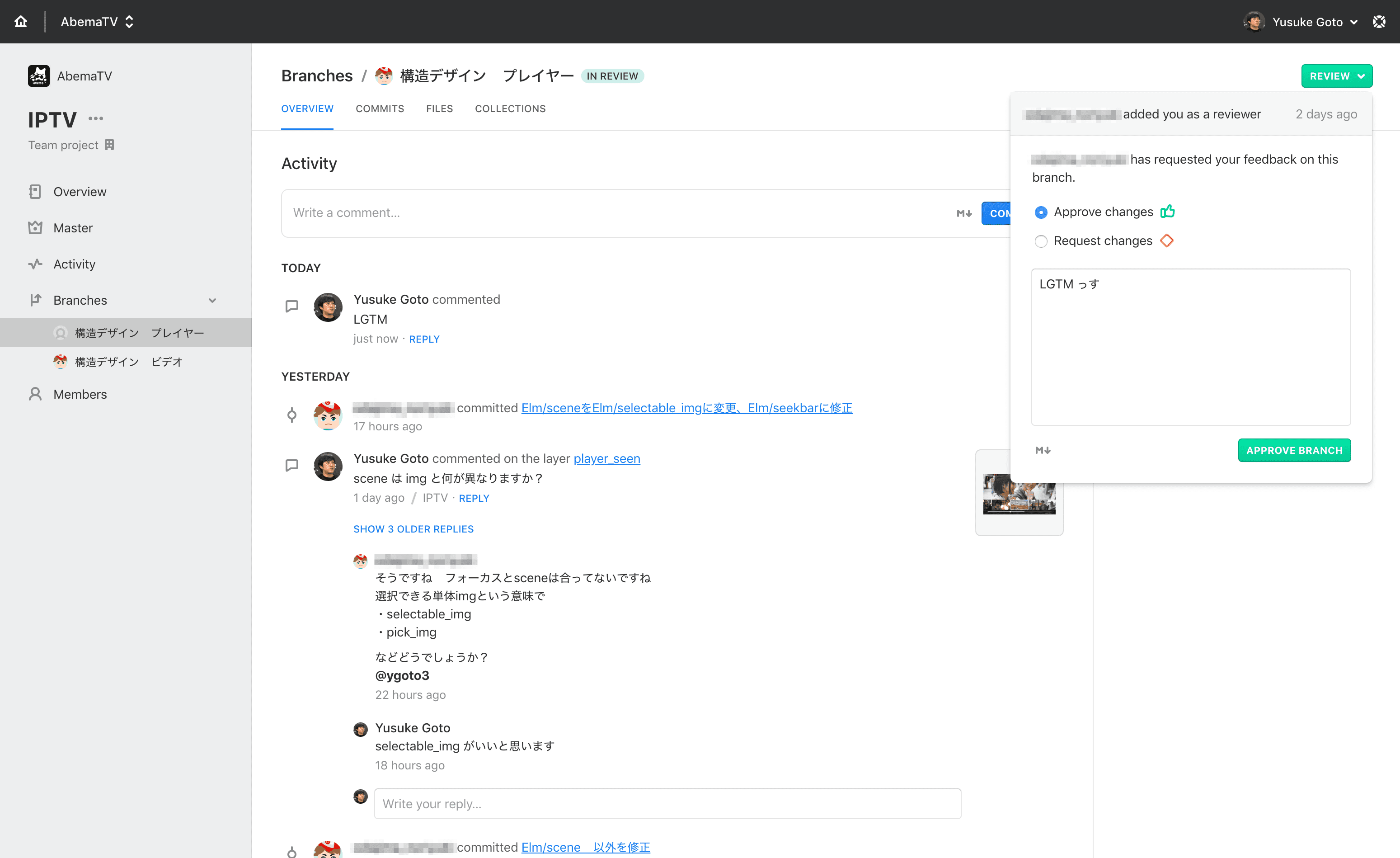
また、複数人の目でデザインレビューをすることも可能になり、デザインの精度も上がります。しかも、ストーリーのデザインはデザイナーに限らずレビューできるので、より他面的に問題を指摘することができます。
ステップ2:デザインの構造化
チームで納得できるストーリーをデザインした後は、後のデザイン工程でそのストーリーが壊れないようにします。まさに Story-Assured Design の名前の由来である ストーリーを保証するステップ です。 How? の部分を作る ステップでもあります。
ストーリーに手段を与える
ストーリーデザインでは「ユーザーが画面からどんな情報を得ることで、次にどんな行動をするか」をデザインしました。デザインの構造化のステップでは「情報をどのように得るか」と「次にどんな手段で行動するか」をデザインします。
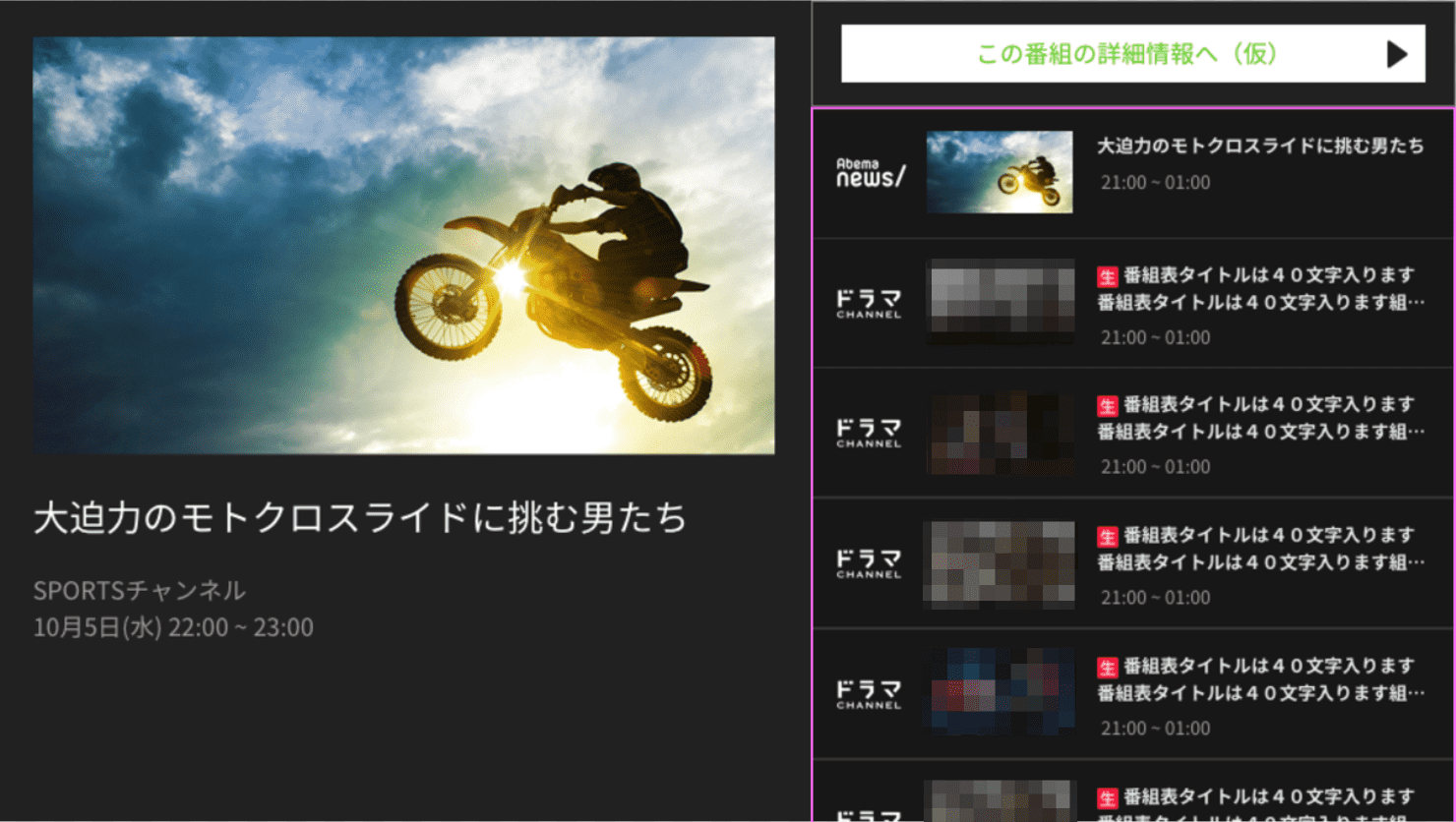
たとえば、上図では、この「この番組の詳細情報へ(仮)」というボタンっぽいものが配置してありますが、実際に手段としてデザインされたのは下図です。
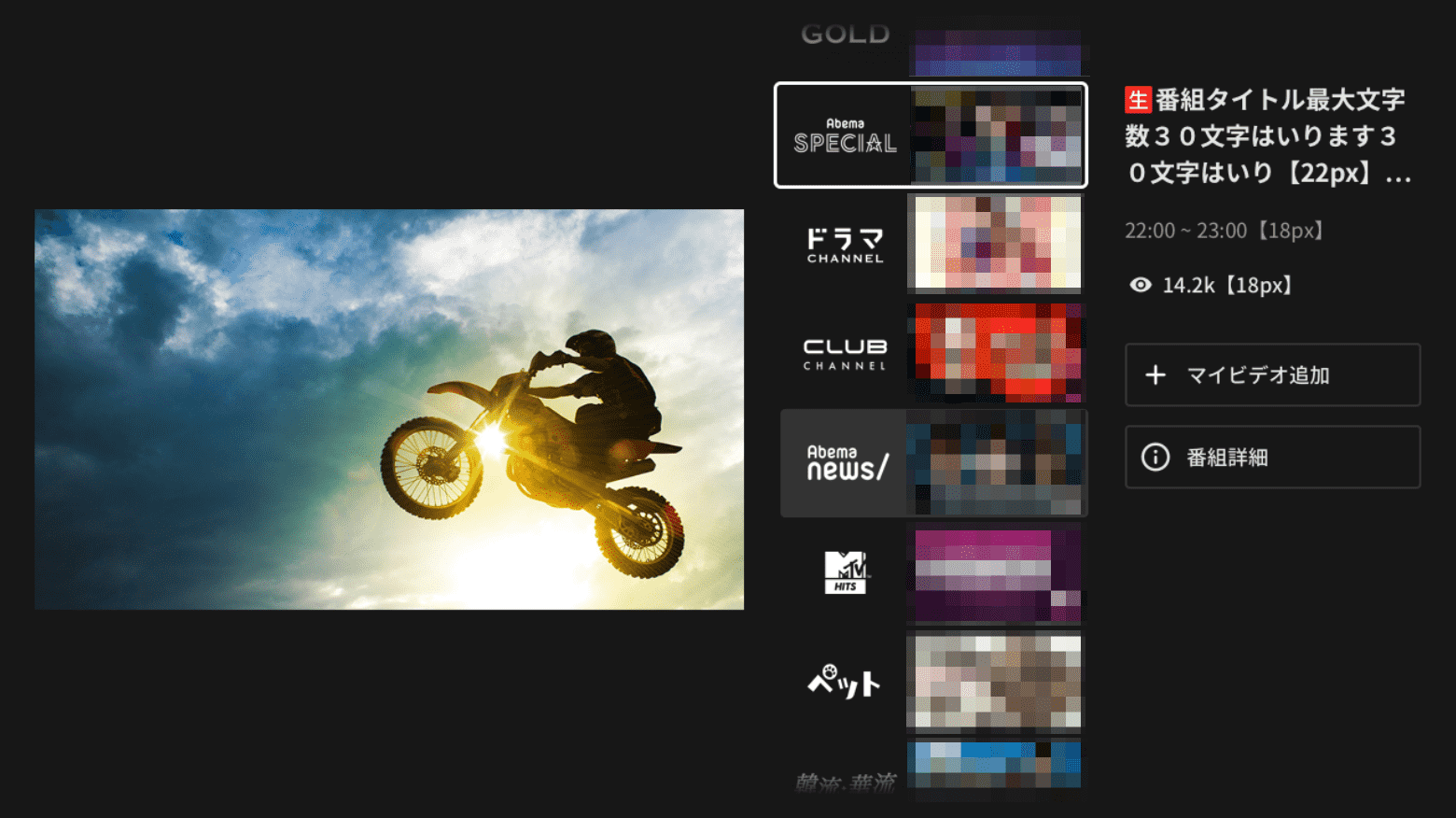
ストーリーデザインの段階では「ユーザーが番組タイトルという情報を受け取って、番組のことをもっと知りたいと思って詳細情報に遷移する」というストーリーにフォーカスを絞ってデザインを考えます。でも、どんな手段で番組タイトルという情報を知って、どんな手段で詳細情報に遷移するか、は詳細に詰める必要はありません。
デザインを構造化するこのステップで、どんな情報の提供方法が一番良いかを詰めます。
ストーリーデザインが壊れる
手段をデザインするとともに、このステップではストーリーを保証します。ストーリーを保証する、というのはストーリーが壊れていないことを保証する、ということです。デザインされたストーリーが壊れる、というのはどういうことかを説明します。これを説明するにはステップ3の視覚情報デザインについて少し話す必要があります。
視覚情報デザイン、というのは簡単に言うと、Sketch などのデザインツールでプロダクトの画面の見た目の最終形を作ることです。いわゆるデザインカンプです。たぶんデザインデータと言われて一番頭に思い浮かぶものだと思います。

いざデザインカンプを作っていく段階になると、視覚的なバランスを調整することになります。このとき、画面上で目に入る要素数が多いから、バランスを取るために UI 要素を減らしたり、バランスを保てる場所に要素を移動させるなどの調整することもあります。このとき視覚的な問題ばかりに気を取られていると、プライマリーストーリーとして決めた一番ユーザーにしてもらいたい行動までの距離が遠くなっていることに気付かないレイアウト修正を行ってしまうことがあります。
ストーリーを構成する要素の構造化
こういった意図しないストーリーデザインの破壊を防ぐため、ストーリーを構成する要素を構造化します。構造化というのは、そのものの構造を見て分かるようにすることです。つまり「デザインの意図を理解しやすくする」ための作業です。構造化によってデザインの意図が見えやすくなると、デザインに変更が入ったときに影響範囲も人目で分かるようになります。
Story-Assured Design では、ストーリーに対する影響と見た目(視覚情報)に対する影響を分離するようにデザインを構造化します。
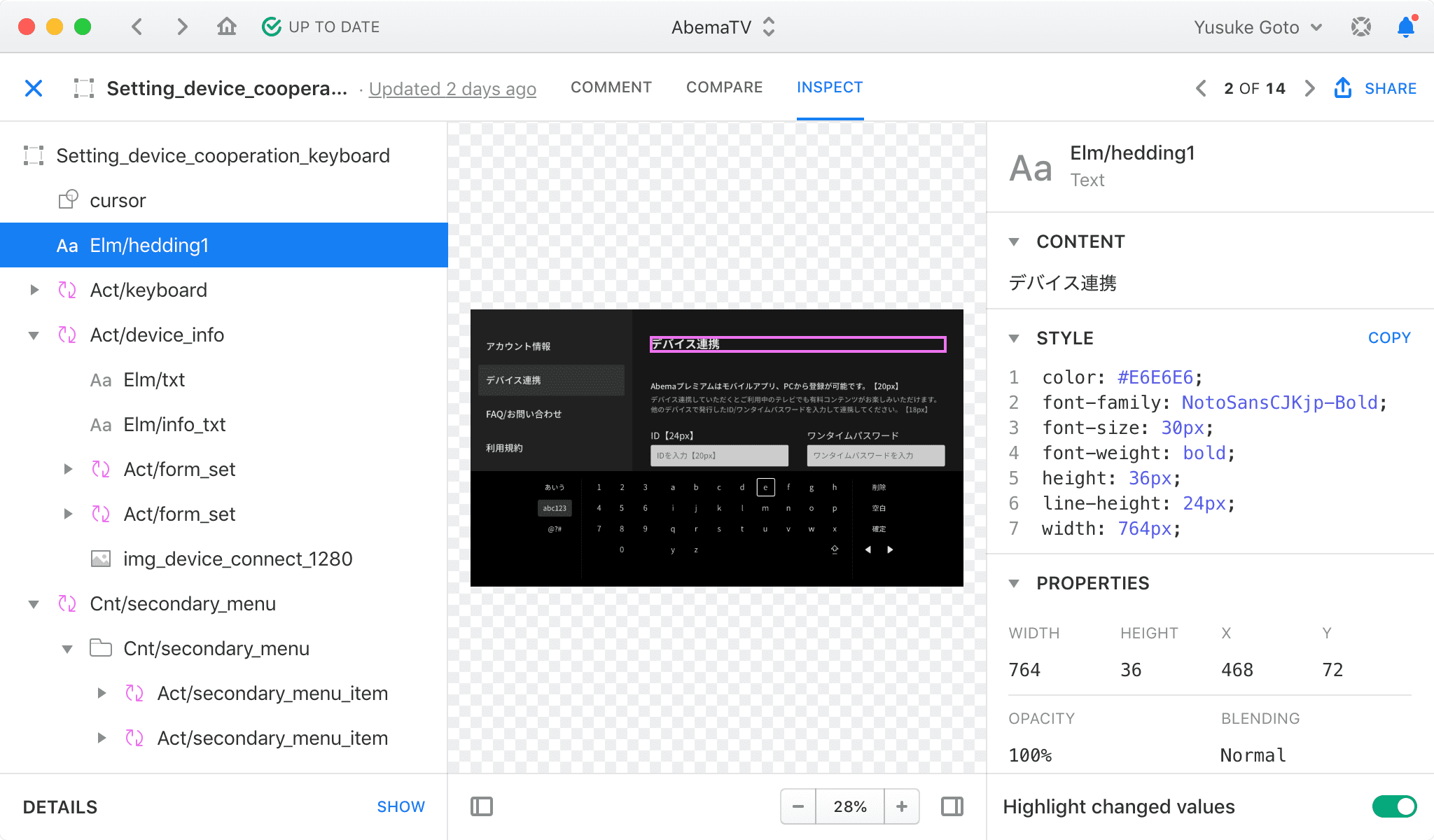
デザインの構造化の作業では、デザインを構成する要素を意味ある単位に分解して整理していきます。具体的な整理の仕方はどんな方法でも構わないのですが、Sketch などのデザインデータ上と実装コード上で表現できるものにします。この2つで表現可能なものでないと仕組みとして変更に対する保証を作ることが難しいからです。
整理の大切さ
引き出しの中の道具を整理するとき、仕切りを作って道具の種類ごとに分類すると思います。これはどこにどんな道具が入ってるか理解しやすくするための構造化です。そのように整理された引き出しは使いやすいはずです。
引き出しは整理されていなくても、文章は書けるし、絵も描けます。なので、作品作りに影響がないという人もいると思います。ただ、その引き出しを個人ではなく複数人で共用で使うことを考えると、整理されていないと道具を探すことに時間がかかりすぎて、何人かの制作作業に支障が出ているかもしれません。新しく引き出しを使う人は確実にすぐには作業に取り掛かれないでしょう。
コンポーネント化による整理
デザインの構造化も引き出しの整理と基本的な目的は同じです。複数人で作業しても制作作業に支障が出ないようにします。引き出しの中にある鉛筆や消しゴム、定規などの道具は個体として識別できるので、個々の配置を変えたり、分類したりすることで整理できますが、デザイン自体はそのままでは整理することができません。そこでデザインを構成する要素を識別可能な形でコンポーネント化すると整理がしやすくなります。
今は Sketch などのデザインツールがコンポーネント化を意識した機能を提供しているため、以前よりコンポーネントベースでデザインすることがかなり一般的になってきて多くの人がイメージしやすくなっています。
デザインからデプロイまでのリードタイムを短くする構造
そして、何よりソフトウェアのコード設計自体がコンポーネントベースであることが多いので、一番理に適っています。デザインにおける検証と実装を繰り返して改善していくのであれば、デザインの構造とコード設計の差をできる限り無くすことが1番デザインからデプロイまでのリードタイムを短くすることができます。
UI コンポーネントに再利用性は必須ではない
デザイン要素をコンポーネント化した、いわゆる UI コンポーネントの話とよくセットで話題に上がるのは、再利用性という言葉です。しかし、Story-Assured Design の中では再利用できるかどうかは UI コンポーネントの必須条件とは考えないようにします。デザインデータの構造化のためにコンポーネント化しているので、再利用できなくてもコンポーネントとして整理します。
デザインにおける関心の分離
デザイン要素をコンポーネント化しようとすると、どのような要素をどういう単位でまとめておくか悩むと思います。私のオススメは「関心の分離」を基準にコンポーネントにまとめるのが良いと思います。そのコンポーネントがどんなデザイン的な課題を解決することに関心(責任)を持たせたいか、という視点でまとめておくと、デザインの意図が構造により理解しやすくなります。
そして、ソフトウェアのコンポーネント化と同様に、単一責任原則に従うとデザインの変更がしやすい構造になるでしょう。「変更する理由が同じものは集める、変更する理由が違うものは分ける」ことで将来的なデザイン改善速度は加速するはずです。
デザインにおける関心の分離の例は、拙著『Atomic Design ~堅牢で使いやすいUIを効率良く設計する』にも書きましたが、UI をコンポーネント化する基準として1番理に適っていると思っています。デザインの構造化に Atomic Design のような階層化された構造を採用するのも良いでしょう。
ここまででモック実装に必要なデザインが完了
データ構造デザインが完了した時点でエンジニアは UI 実装に着手できるようになります。今回のプロジェクトでは Sketch のデータ構造どおりに UI をコードに実装していきました。
ここで実装された UI は視覚情報がまだデザインされていないので、実装されたアプリケーションはまだモックのようなものですが、デザインしたユーザーストーリーはそのまま反映されているはずです。なので、このモックではデザインされたユーザーストーリーが正しく機能しているかを評価することができます。
また、実装と平行して、次のステップで紹介する視覚情報デザインを進めることができます。これにより、実装においてデザインを待つ時間が短かくなります。そして、ユーザーストーリーを自分たちで先行して触って評価することもできるので、視覚情報のデザインを詰めすぎる前にフィードバックを得ながらユーザーストーリーに改善していき、最終的なデザインへと詰めていくことができます。
ステップ3:視覚情報デザイン
Story-Assured Design の最後のステップは視覚情報のデザインです。視覚情報のデザインというとまどろっこしいですが、一般的に多くの人が思い浮かべるであろうデザイン作業です。私たちのチームではよく「デザインカンプの作成」と言っていました。 ユーザーが見る画面に限りなく近い最終形のデザインを Sketch データとして作ります 。プロダクトデザインにおける What を作る 工程です。

ユーザーの満足度を決めるデザイン
ストーリーデザインでは事業利益に貢献することに比重を置いてデザインしましたが、このステップでは、ユーザーの満足度を最大限高めることに比重を置いてデザインします。
視覚情報デザインはその名前の通り、ユーザーに視覚的に伝えるあらゆる情報をデザインすることを指します。ストーリーでデザインした情報の流れがユーザーにどのように見せられて、どう伝わるかが改めてデザインされます。細やかな工夫で直感的に情報が伝わり、ストレスない使用感に繋ります。この工程次第でユーザーの満足度は大きく変わります。
構造を保ったまま見た目をデザインする
Story-Assured Design において視覚情報をデザインする際は、前のステップで作った構造を保ったまま見た目だけをデザインしていきます。前述したとおり、構造デザインはデザインしたストーリーが壊れていないことを保証するためのステップです。その構造に変化を加えてしまうとストーリー自体を破壊してしまう可能性があります。Story-Assured Design では構造化されたデザイン自体をストーリーデザインに対するリグレッション(退行)テストだと捉えることができます。
構造に変更が発生する場合はストーリーデザインから修正する
とはいえ、視覚情報をデザインしていると、どうしても構造に変更を加える必要が出てくる場合はあります。そんなときは、構造に変更を加えます。ただし、先程構造化されたデザインはストーリーデザインに対するリグレッションテストだと書いた通り、構造に変更を加えた場合はストーリーデザインから見直しを行います。構造の変化により、デザインされたストーリーに矛盾があったり、成り立たなくなっていることが確認された場合はストーリーデザイン自体をやり直します。そして、デザインの構造化を再度行い、最後にデザインカンプに戻って修正を反映します。
視覚情報デザインではデザイナーの意見を優先させる
先述した通り、視覚情報デザインだけは作業にもレビューにも、どうしてもグラフィック能力に長けている必要がある場合が多いです。この領域はデザイナーが担保します。視覚情報デザイン以外のステップでは、チームメンバーの意見は常に平等に扱われることが大事です。明文化された KPI があるため、誰でも同じゴールを向いた意見を言うことが可能だからです。しかし、視覚情報デザインのステップだけはデザイナーの意見を優先させることが大事だと個人的には思っています。視覚情報デザインは非言語的な要素を扱うことが多く、言葉だけでレビュー観点を合わせることが困難です。
デザイン原則の必要性
言葉だけでレビュー観点を合わせることが困難だと言っても、視覚情報デザインをデザイナーだけに任せてしまうということではありません。視覚情報デザインにおいても言葉にしきれないギリギリのところまではチーム全員が良さを評価できる指針を作ります。
ユーザー満足を追求するときに一番身近なユーザーは自分です。そのため、このステップでは特にお互いが考える『良い』をぶつけ合いやすくなります。ぶつけ合いを防ぐために自分たちが考える良いユーザー体験をしっかり定義することが大事です。実際にユーザーがどういう体験を得ることを期待するのかを言語化します。
そのためには、自分たちが開発するプロダクトやサービスにとってのデザイン原則を作るのがオススメです。この原則を視覚情報デザインに限らず、全体のデザイン指針にします。
- 最小限のボタン操作数でやりたい操作ができること
- カーソルを一度移動させるなど直近の操作に依存することなく、常にカーソルの位置が明確であること
- 操作時に目線の移動が少ないこと
- 操作に対して行くときと戻るときの物理的、心理的な距離が常に一定であること
上記は一部ですが、ユーザー体験を考える際に「Aの案の方がユーザー体験が良い」というより「Aの案はカーソルの移動距離が小さく、ユーザーは目線を移動させる必要がないため、楽に操作ができる」というように原則に沿っているかという目線で話し合いができる方がチームが考える『良い』への結論に早く導くことができます。
作って思いますが、最初から完璧なデザイン原則を作ることは難しいと思います。ただそれでも、何かを言葉にしてから先に進む、ということが大事です。決定が間違っていれば、少なくともどこかで間違いに気付くことができ、修正することもできます。修正すれば前進しています。しかし、難しいからと言って何も決めなければ、いろいろな人にとっての良いユーザー体験が詰め込まれ、結果的に、誰にとってもどのように使ってもそこそこな体験を提供するデザインになってしまいます。
リリース後にストーリーデザインを定量評価
ここまでストーリーを明確にしてデザインしてきたので、リリース後はそのデザインが本当にワークしているかが分かります。アクセス解析ツールでユーザーがストーリーデザイン通りに行動をしているかを定量的に評価することができるからです。今回のプロジェクトでは Google Analytics の「行動フロー」でユーザーの実際の行動とストーリーデザインとの差異を確認しました。
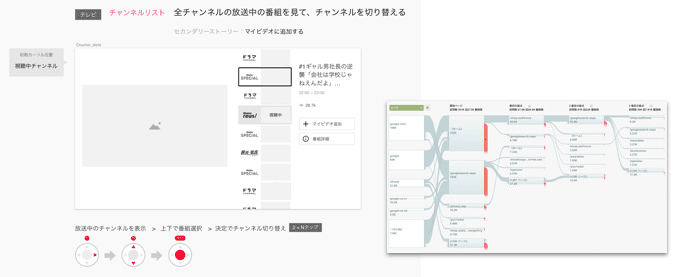
ファクト(事実)を基にストーリーデザインを改善する
ユーザーの行動を解析していくとストーリーデザインで描いたものと異なる結果も出てきます。解析ツールで確認できるユーザーの行動は紛れもないファクト(事実)なので、リリース後はこのファクトを明確に変化させるようにストーリーデザインを改善していきます。
効果的に意図する方向にファクトを変化させるためにはユーザーの行動理由を分析する必要がありますが、解析ツールで得られる数字だけでユーザー行動の全てを理解することは困難です。ある程度仮説を立てた後は、実験的にストーリーをリリースしてファクトの変化を観測しながら分析する方が間違いもなく確実です。ファクトからユーザーの行動理由を推測できるものもありますが、どうしても推測できないものもあると思います。ユーザーテストなどのより直接的な手段も活用していきます。
より分析しやすくなるようにデザインすることも重要です。「デザインの構造化」で触れた「デザインにおける関心の分離」がうまく設計されていると、分析したい行動に関わる要素だけを変更させることが簡単にできるため、有意な差異に辿り着きやすくなります。「デザインの構造化」によりコード側の構造もデザインの構造と同じになっているため、実装も容易なはずです。
タスクをストーリー駆動で管理する
組織やチームが大きくなってくると、大人数で分業するために作業を多数のタスクに分割して管理することになりますが、分割されたタスクが「それをやる理由」と切り離されて管理されてしまうことがあります。タスクには最低限「何をやるか」が記されていれば実行可能なため、「なぜやるか」までは記されずに担当者に渡されることがいつしか普通になってしまう現象です。
タスク自体が「何をやるか」だけ理解された上で実行されてしまうと、意図と異なった仕上がりになってしまうリスクがあります。担当者にとってもただの作業となってしまい工夫の余地もないため、せっかくチームに高い能力を持ったメンバーがいても、力を活かしきることができなくなります。
これを防ぐため、タスクは基本的にストーリー駆動で管理するようにします。プロジェクト管理ツールなどを使ってタスクをチケット管理している場合は、ストーリーチケットを常にタスクチケットの親として管理するのがオススメです。
ストーリーに紐付くタスクは、「仕様化」、「ストーリーデザイン」、「デザインの構造化」、「視覚情報デザイン」、「実装」、「ログ設計」、「ログ実装」などになります。「ログ設計」、「ログ実装」以外はストーリーをリリースするために常に必要なタスクです。ストーリーは常にユーザーの行動に変化を与えるために作られるため、KPI を持ちます。そのため、その KPI が新しいストーリーデザインによってどう変化したか計測する必要があるので、既存のログ設計で計測できない場合は「ログ設計」と「ログ実装」がタスクとして追加されます。
それぞれのタスクのレビューは、「紐付いているストーリーが持つ KPI を効果的に改善できるように工夫されているか」という視点でチーム全員が目線を合わせて行うことができます。
実践してみて
Story-Assured Design のワークフローを実践した結果、初期リリース直前のデザインのブラッシュアップ速度は凄まじいものになりました。ストーリーが構造化によって保証されている状態なので、ギリギリのタイミングまで細かいユーザビリティ改善を心理的安全性が高い状態で行うことができました。
また、構造化されたデザインがコード設計と同期しているため、どの要素をいじれば実装にどの程度影響があるかも分かるのも大きかったと思います。影響範囲が大きいことが分かった場合にすぐに同じ問題を解決する別のデザイン手段に切り替えることができます。
そして何より、チーム全員がデザインに取り組んでいる状態は、それぞれが事業利益とユーザー体験を向上するために考えて工夫することを可能にするため、相乗効果を生みました。初期リリース直前の KPT ではデザインに関する多くの Keep や Problem が出たことは、1つの成功体験になったと感じます。

またこのワークフローで作られたデザインデータも思わぬ副産物を生んでいます。ストーリーデザインの Sketch データは見ることでプロダクト全体のユーザーストーリーを把握できるため、テスト設計者やログ設計者もこれを参照してテスト設計やログ設計を行いました。ユーザーストーリーに対する理解があることで、テストやログ設計者も柔軟に設計しやすくなりました。
このデザインワークフローはプロダクトの成長に伴なって確実なデザインの改善スピードを上げていくことが目的です。ここからの道程が本番なので、品質が高い改善スピードを向上させられるように進めていきたいと思います。
終わりに
現在も Story-Assured Design のワークフローで改善を繰り返しています。しかし、サービスはどんどん成長していき、組織規模のスケールに伴なった課題の難易度も増していっています。そのため、次のアプローチとして DesignOps を模索しています。このまま組織が大きくなったとしても、デザインに関するオペレーションを正しく効率化でき、クリエイティビティを常に最大限にできたら最高です。その中で Story-Assured Design のようなワークフローもその1つの構成要素として更に上手く機能させることができたらなと思っています。
]]>